モデル情報
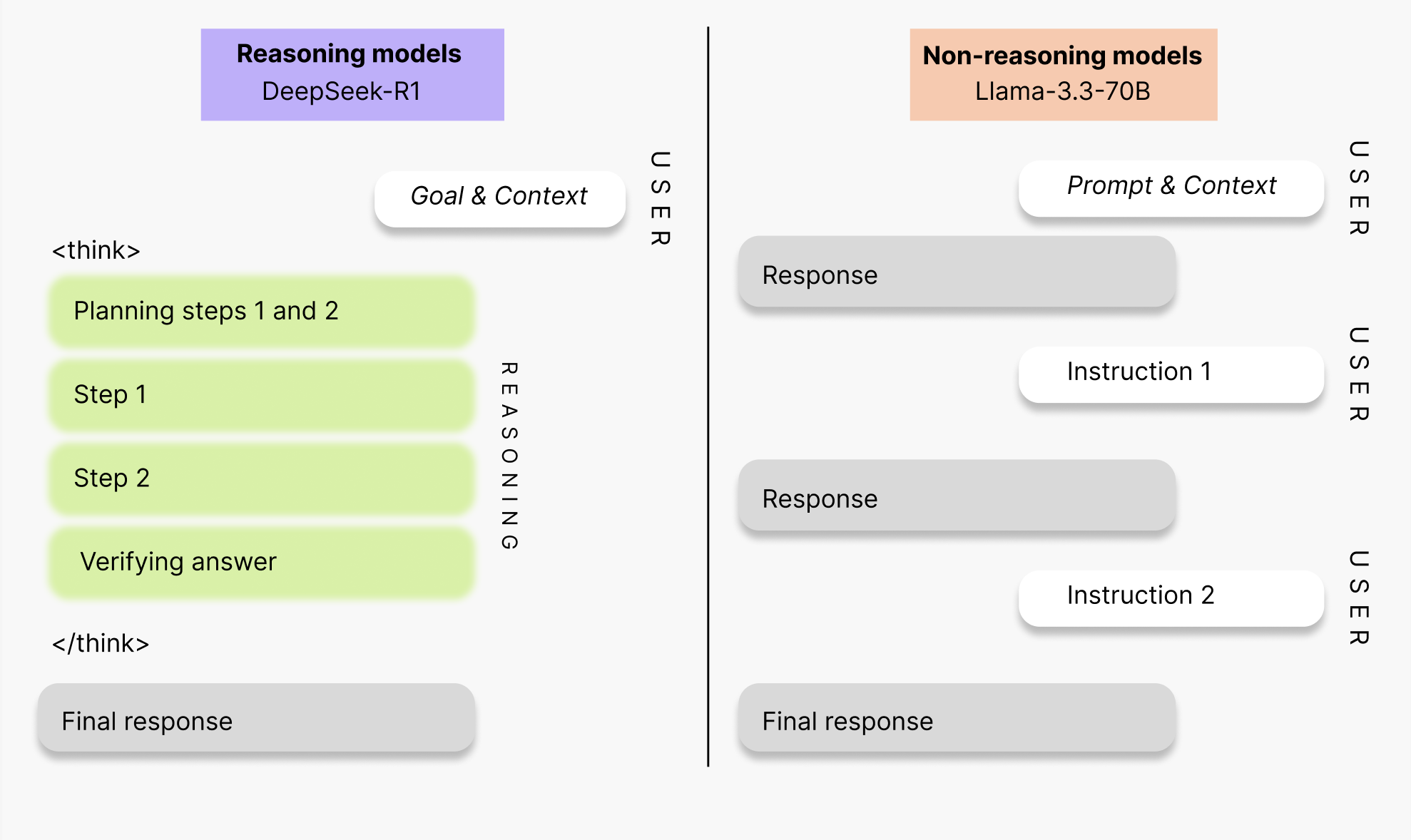
DeepSeek-R1は6,710億パラメータを持つオープンソースのReasoningモデルです。このモデルの特徴は、ユーザープロンプトにどのように応答するべきかを熟考するための思考用トークンを用いている点にあります。これらのトークンは、出力内に<think>タグとして表示されます。このような構造上の違いがあるため、通常のモデルとは異なる使い方やプロンプト設計が求められます。詳細は以下をご覧ください。
システムプロンプトの設計
- 指示的なシステムプロンプトは削除し、ユーザークエリ以外の追加プロンプトは最小限にしてください。過度な指示はモデルの思考範囲を制限し、出力品質を低下させる可能性があります。
ユーザープロンプトの設計
- Reasoningモデルは、クエリに対して自律的に思考プロセスを行う設計となっているため、CoTを明示的に促すプロンプトや、応答方法を詳細に指示する必要はありません。複雑なタスクに対しては、ゼロショットまたは単一の指示によるシンプルな自然文のプロンプトを使用することが推奨されます。このようなプロンプト設計により、モデルが本来備えているreasoning能力をより効果的に引き出すことが可能になります。
- プロンプト設計にあたっては、目的、出力形式、注意事項、文脈情報などのセクションを、試行錯誤しながら最適な形に調整してください。
- まれに
<think>タグが出力に反映されない場合がありますが、その際はプロンプト内で<think>タグから出力を開始するように明示することで、使用を強制できます。 - 生成される思考ステップを簡潔化するためには、Chain-of-Draftの考え方が有効です。たとえば、「各思考ステップのドラフトは最小限に保ち、最大5単語までとする (only keep a minimum draft for each thinking step, with 5 words at most)」などの制約をプロンプトに追加します。
推奨パラメータ
- 一般的な (数学以外の) reasoningタスクには、
temperature = 0.6、top-p = 0.95の設定を推奨します。より事実重視の応答が望ましい場合、temperature = 0.5など、より低い値に設定することをおすすめします。 - 数学的なreasoningタスクには、
temperature = 0.7、top-p = 1.0の設定を推奨します。
リクエスト例
主な活用例
レポート生成
DeepSeek-R1などのReasoningモデルは、非構造化データの処理が得意で、法律文書、財務諸表、学術論文などの複雑な資料を分析するのに適しています。情報の多角的な側面を分析し、全体を要約することで、有用なレポートを生成できます。 プロンプト例自動運転車の現状について包括的なレポートを作成してください。各セクションごとに内容を整理し、簡潔な要約を示してください。実績を引用する際は、その実績や貢献を行った適切な組織名を明記してください。前提として、私はこの分野に詳しく、自動運転システムの技術にも精通しています。これまでAI分野でキャリアを積んできましたが、自動運転に特化した企業にはまだ所属したことはありません。キャリアチェンジを検討しており、現状のエコシステムを理解したいと考えています。
Develop a comprehensive report on the state of autonomous vehicles. Present this report with organized sections and a breif summarization. Be careful to cite the achievements with the proper entity that made that achievement or contribution. For context: I am knowledgable in this field and have a technical understanding of autonmous vehicle systems. I've been working most of my career in artificial intelligence but have not yet joined a company with the sole focus of autonomous vehicles. I am considering making the career change and wanted to understand the current ecosystem before I go through the job search process.
ワークフローやエージェントの「プランナー」
Reasoningモデルは、曖昧で複雑なタスクに強く、複雑な問題を分解し、戦略を立て、大量の曖昧な情報に基づいて決定を下すことができます。DeepSeek-R1は、こうした複雑な多段階の問題に対する戦略的プランナーとして活用できます。タスクを分解し、詳細な解決策を立案するだけでなく、エージェントシステム内の特定のサブタスクに対して他のAIモデルを割り当てる調整役としても機能します。 Reasoningモデルによる高度な計画立案能力を実際に体感していただくために、こちらのデモアプリではDeepSeek-R1をプランナーとして実装しています。アプリ内では、Deep Research、Financial Analysis、Sales Leadsなど、多様なワークフローを担うエージェントが連携する構成となっています。オープンソースとして公開しており、開発者はこの仕組みをベースに、独自のエージェントワークフローを手軽に実験・構築できます。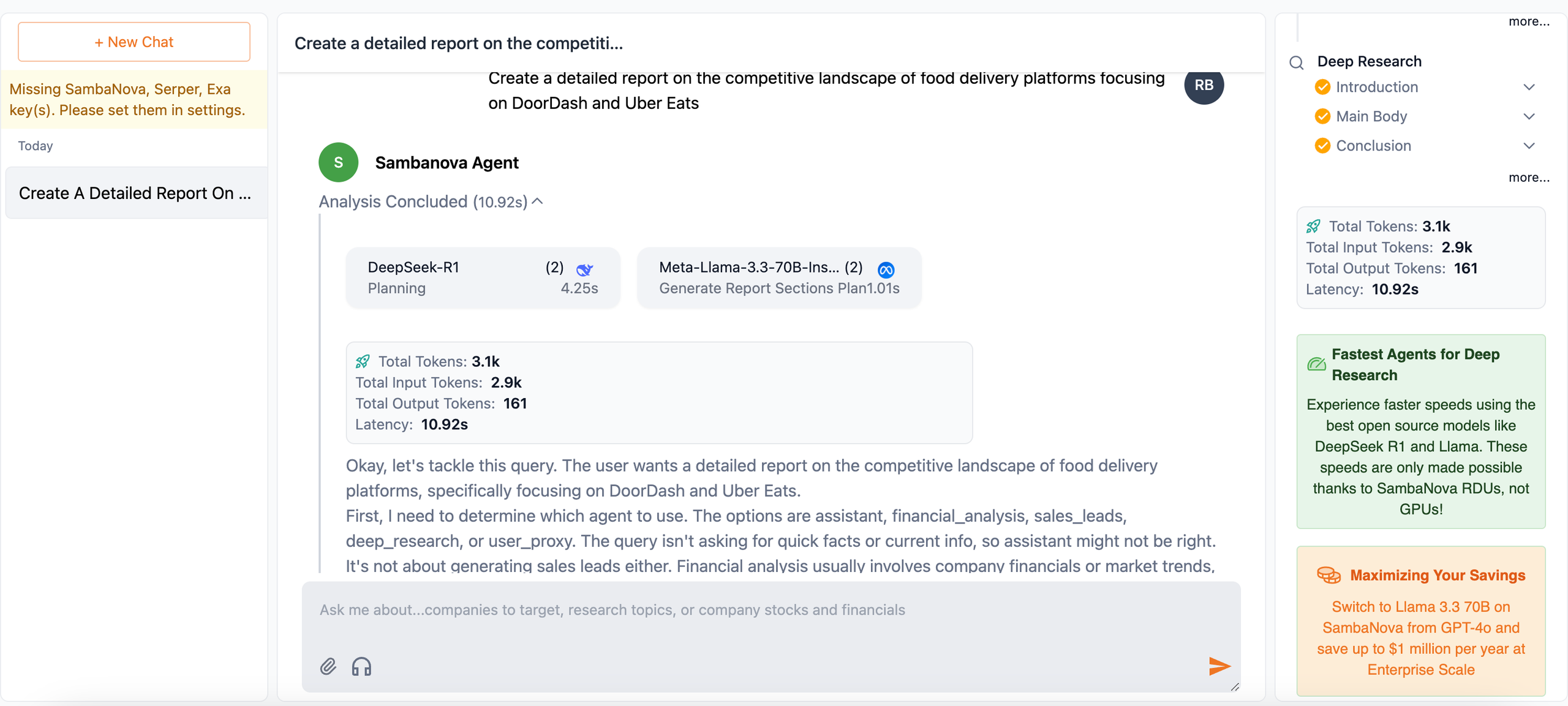
コーディングや数学のサポート
Reasoningモデルはコードのレビューや修正にも有効で、人間では見落としやすい細かな変更も検出できます。また、数学の問題を複数のステップに分解し、それぞれを検証しながら解いていくプロセスにおいても、Reasoningモデルは力を発揮します。ベストプラクティス
レイテンシと費用
レイテンシと費用
Reasoningモデルは
<think>プロセスを伴うため、応答のレイテンシやトークン使用量が長大になる傾向があります。予算や応答時間のニーズを最適化するために、単純なタスクには非Reasoningモデルの利用を検討してください。Reasoningモデルは、ユーザープロンプトをより包括的に捉えるという利点がありますが、その分、ひとつの回答を生成するために多くのトークンと時間を必要とします。こうした特性を最大限活かすためにも、用途に応じてモデルを適切に使い分けることが重要です。ストリーミング
ストリーミング
DeepSeek-R1を使用するアプリケーションでは、ストリーミングを有効にすることで、ユーザー体験を向上させることができます。ストリーミングによりトークンを順次表示させることで、待ち時間やそれに伴う心理的負担を軽減できます。この機能を有効化するには、モデルリクエストに
stream=Trueを追加してください。Function calling
Function calling
DeepSeek-R1における現状のFunction callingの実装は不安定であり、DeepSeekのドキュメントでも指摘されているように、ループ呼び出しや空の応答が発生することがあります。プロンプトエンジニアリングによって試行錯誤である程度対処することは可能ですが、他のモデルを使用する方がより確実です。Llama-3.3-70Bなどの対応モデルによるFunction callingについては、Function callingとJSONモードのページをご参照ください。
よくある質問
DeepSeek-R1の最大コンテキスト長に関して、「BadRequestError: 400」が発生しました。関連情報はどこで確認できますか?
DeepSeek-R1の最大コンテキスト長に関して、「BadRequestError: 400」が発生しました。関連情報はどこで確認できますか?
このモデルは中国企業が開発したと聞きましたが、どこでホスティングされていますか?
このモデルは中国企業が開発したと聞きましたが、どこでホスティングされていますか?
主に米国のデータセンターでホスティングしており、一部は日本国内のデータセンターでも稼働しています。
このモデルのアクセス方法を教えてください。
このモデルのアクセス方法を教えてください。
まずはPlayground上でモデルをお試しください。利用可能になり次第、APIキーを取得してアクセスできます。